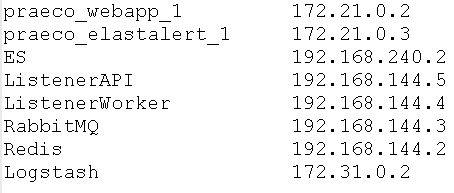
Следующая команда поможет вывести имена и IP адреса контейнеров Docker в виде таблицы. Очень удобно при поиске нужно адреса контейнера Docker. Читать далее «Как вывести имена и IP адреса контейнеров Docker»
docker
Шпаргалка по командам Docker (Cheat Sheet)

В этой статье собран список самых нужных команд по Docker: установка, запуск контейнеров, управление контейнерами, сетями и так далее. Читать далее «Шпаргалка по командам Docker (Cheat Sheet)»
Что такое Kubernetes

Введение
Kubernetes — это мощная система с открытым исходным кодом, изначально разработанная Google, для управления контейнерными приложениями в кластерной среде. Он призван обеспечить более эффективные способы управления связанными, распределенными компонентами и сервисами в рамках разнообразной инфраструктуры.
В этой статье мы обсудим некоторые основные понятия Кубернетеса. Мы поговорим об архитектуре системы, проблемах, которые она решает, и модели, которую она использует для обработки развертываний и масштабирования в контейнерах.
Что такое Кубернетис?
Kubernetes представляет собой систему для запуска и управления контейнерными приложениями в кластере. Это платформа, предназначенная для полного управления жизненным циклом контейнерных приложений и сервисов с использованием методов, обеспечивающих предсказуемость, масштабируемость и высокую доступность.
Вы можете определить, как должны работать Ваши приложения и каким образом они должны взаимодействовать с другими приложениями или внешним миром. Вы можете масштабировать свои службы (в обе стороны), выполнять постепенные обновления и переключать трафик между различными версиями своих приложений для тестирования функций или отката проблемных развертываний. Kubernetes предоставляет интерфейсы и составные платформы, которые позволяют Вам определять и управлять своими приложениями с высокой степенью гибкости, мощности и надежности.
Архитектура Kubernetes
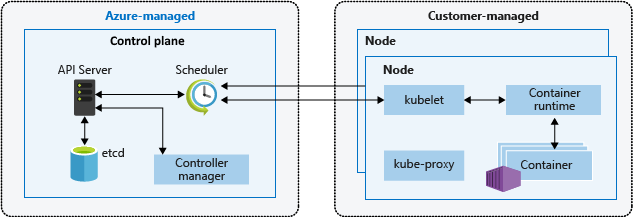 Чтобы понять, как Kubernetes может предоставить все эти возможности, необходимо получить представление о том, как он устроен. Kubernetes можно визуализировать как систему, построенную из слоев, причем каждый более высокий уровень абстрагирует сложность, обнаруженную на более низких уровнях.
Чтобы понять, как Kubernetes может предоставить все эти возможности, необходимо получить представление о том, как он устроен. Kubernetes можно визуализировать как систему, построенную из слоев, причем каждый более высокий уровень абстрагирует сложность, обнаруженную на более низких уровнях.
В своей основе Kubernetes объединяет отдельные физические или виртуальные машины в кластер, используя общую сеть для связи между каждым сервером. Этот кластер является физической платформой, в которой настроены все компоненты, возможности и рабочие нагрузки Kubernetes.
Каждому из компьютеров в кластере отводится роль в Kubernetes. Один сервер (или небольшая группа в высокодоступных развертываниях) функционирует как главный сервер (Master Node). Этот сервер действует как шлюз и мозг для кластера, предоставляя API для пользователей и клиентов, проверяя работоспособность других серверов, решая, как лучше разделить и назначать работу (известную как «планирование»), и организуя связь между другими компонентами. Главный сервер выступает в качестве основной точки контакта с кластером и отвечает за большинство централизованной логики, которую предоставляет Kubernetes.
Другие машины в кластере обозначены как узлы (Worker Node) — серверы, отвечающие за принятие и выполнение рабочих нагрузок с использованием локальных и внешних ресурсов. Чтобы помочь с изоляцией, управлением и гибкостью, Kubernetes запускает приложения и службы в контейнерах , поэтому каждый узел должен быть оснащен средой выполнения контейнера (например, Docker или rkt). Узел получает рабочие инструкции от главного сервера и, соответственно, создает или уничтожает контейнеры, корректируя сетевые правила для соответствующей маршрутизации и пересылки трафика.
Как упоминалось выше, сами приложения и службы запускаются в кластере внутри контейнеров. Базовые компоненты гарантируют, что требуемое состояние приложений соответствует фактическому состоянию кластера. Пользователи взаимодействуют с кластером, общаясь с главным сервером через API напрямую или с клиентами и библиотеками. Чтобы запустить приложение или службу, в JSON или YAML передается план, определяющий, что создавать и как управлять. Главный сервер затем берет план и выясняет, как запустить его в инфраструктуре, изучая требования и текущее состояние системы. Эта группа пользовательских приложений, работающих в соответствии с указанным планом, представляет последний уровень Kubernetes.
Компоненты главного сервера (Master Node Server)
Как мы описали выше, главный сервер выступает в качестве основной плоскости управления для кластеров Kubernetes. Он служит главной контактной точкой для администраторов и пользователей, а также предоставляет множество систем для всего кластера для относительно простых рабочих узлов. В целом, компоненты на главном сервере работают вместе, чтобы принимать пользовательские запросы, определять наилучшие способы планирования контейнеров рабочей нагрузки, проверять подлинность клиентов и узлов, настраивать сети на уровне кластера и управлять масштабированием и проверкой работоспособности.
Эти компоненты могут быть установлены на одном компьютере или распределены по нескольким серверам. Сейчас мы рассмотрим каждый из отдельных компонентов, связанных с главными серверами.
etcd
Одним из фундаментальных компонентов, который должен функционировать в Kubernetes, является глобально доступное хранилище конфигурации. Etcd, разработанный командой в CoreOS, это легкое, распределенное хранилище (ключ), которое может быть сконфигурировано для использования на нескольких узлах.
Kubernetes использует etcd для хранения данных конфигурации, которые могут быть доступны для каждого из узлов в кластере. Это может использоваться для службы обнаружения (discovery service) и может помочь компонентам настроить или перенастроить себя в соответствии с актуальной информацией. Это также помогает поддерживать состояние кластера с такими функциями, как выбор лидера и распределенная блокировка. Предоставляется простой HTTP/JSON API интерфейс для установки или получения значений.
Как и большинство других компонентов в плоскости управления, etcd можно настроить на одном главном сервере или распределить по нескольким машинам. Единственное требование состоит в том, чтобы он был доступен по сети каждому из хостов Kubernetes.
kube-apiserver
Одним из наиболее важных основных сервисов является сервер API. Это основная точка управления всего кластера, поскольку она позволяет пользователю настраивать рабочие нагрузки и организационные единицы Kubernetes. Он также отвечает за то, чтобы убедиться, что хранилище etcd и детали обслуживания развернутых контейнеров согласованы. Он служит мостом между различными компонентами для поддержания работоспособности кластера и распространения информации и команд.
Сервер API реализует интерфейс RESTful, это означает, что множество различных инструментов и библиотек могут легко взаимодействовать с ним. Клиент под названием kubectl доступен как метод по умолчанию для взаимодействия с кластером Kubernetes с локального хоста.
kube-controller-manager
Диспетчер контроллеров (controller-manager) — это общая служба, на которую возложены многие обязанности. Прежде всего, она управляет различными контроллерами, которые регулируют состояние кластера, управляют жизненными циклами рабочей нагрузки и выполняют рутинные задачи. Например, контроллер репликации гарантирует, что количество реплик (идентичных копий), определенных для модуля, соответствует числу, развернутому в данный момент в кластере. Подробная информация об этих операциях записывается в etcd, где диспетчер контроллера следит за изменениями через сервер API.
Когда изменение замечено, контроллер считывает новую информацию и реализует процедуру, которая удовлетворяет желаемому состоянию. Это может быть масштабирование приложения, настройку конечных точек и так далее.
kube-scheduler
Процесс, который фактически назначает рабочие нагрузки определенным узлам в кластере, является планировщиком. Этот сервис считывает требования рабочей нагрузки, анализирует текущую инфраструктурную среду и размещает работу на приемлемом узле или узлах.
Планировщик отвечает за отслеживание доступной емкости на каждом хосте, чтобы убедиться, что рабочие нагрузки не запланированы сверх доступных ресурсов. Планировщик должен знать общую емкость, а также ресурсы, уже выделенные для существующих нагрузок на каждом сервере.
cloud-controller-manager
Kubernetes может быть развернут во многих различных средах и может взаимодействовать с различными поставщиками инфраструктуры для понимания и управления состоянием ресурсов в кластере. В то время как Kubernetes работает с общими представлениями ресурсов, такими как подключаемое хранилище и балансировщики нагрузки (attachable storage и load balancers), ему нужен способ сопоставить их с реальными ресурсами, предоставляемыми неоднородными облачными провайдерами.
Менеджеры облачных контроллеров действуют как связующее звено, которое позволяет Kubernetes взаимодействовать с поставщиками с различными возможностями, функциями и API-интерфейсами, поддерживая при этом относительно общие конструкции внутри. Это позволяет Kubernetes обновлять информацию о своем состоянии в соответствии с информацией, полученной от облачного провайдера, корректировать облачные ресурсы по мере необходимости изменений в системе, а также создавать и использовать дополнительные облачные сервисы для удовлетворения рабочих требований, представленных кластеру.
Компоненты сервера-узла (Worker Node Server)
В Kubernetes серверы, которые выполняют работу (запуск контейнеров) называются worker (воркер). Узловые серверы предъявляют несколько требований, необходимых для взаимодействия с главными компонентами, настройки сетей контейнеров и выполнения фактически назначенных им рабочих нагрузок.
Контейнер Runtime
Первый компонент, который должен иметь каждый узел, это среда выполнения контейнера. Как правило, это требование удовлетворяется путем установки и запуска Docker, но также доступны альтернативы, такие как rkt и runc .
Среда выполнения контейнера отвечает за запуск и управление контейнерами, приложениями, инкапсулированными в относительно изолированной, но легкой рабочей среде. Каждая единица работы в кластере на своем базовом уровне реализована в виде одного или нескольких контейнеров, которые должны быть развернуты. Среда выполнения контейнера на каждом узле — это компонент, который в конечном итоге запускает контейнеры, определенные в рабочих нагрузках, переданных в кластер.
kubelet
Основной точкой контакта для каждого узла с кластерной группой является небольшой сервис под названием kubelet . Эта служба отвечает за передачу информации в службы уровня управления и обратно, а также за взаимодействие с etcd хранилищем для чтения сведений о конфигурации или записи новых значений.
Kubelet обменивается данными с мастер-сервером — компонентами для аутентификации в кластере, прием команд и работу. Работа принимается в форме манифеста (manifest), который определяет рабочую нагрузку и рабочие параметры. Затем kubelet берет на себя ответственность за поддержание состояния работы на worker сервере (сервере-узле). Он контролирует время выполнения контейнера для запуска или уничтожения контейнеров по мере необходимости.
kube-proxy
Для управления подсетями отдельных хостов и предоставления услуг другим компонентам на каждом сервере узла запускается небольшая прокси-служба, называемая kube-proxy. Этот процесс перенаправляет запросы в правильные контейнеры, может выполнять примитивную балансировку нагрузки и, как правило, отвечает за то, чтобы сетевая среда была предсказуемой и доступной, но, при необходимости, изолированной.
Объекты и рабочие процедуры (Objects и Workloads)
В то время как контейнеры являются базовым механизмом, используемым для развертывания приложений, Kubernetes использует дополнительные уровни абстракции через интерфейс контейнера, чтобы обеспечить функции масштабирования, отказоустойчивости и управления жизненным циклом. Вместо непосредственного управления контейнерами пользователи определяют и взаимодействуют с экземплярами, состоящими из различных примитивов, предоставленных объектной моделью Kubernetes. Ниже мы рассмотрим различные типы объектов, которые можно использовать для определения этих рабочих процедур.
Модуль pod
Для запуска экземпляров приложения Kubernetes использует модули pod. Каждый pod соответствует одному экземпляру приложения. Обычно с каждым контейнером сопоставляется ровно один pod, но в некоторых сложных сценариях pod может содержать несколько контейнеров. Такие pod с несколькими контейнерами назначаются одному узлу и позволяют контейнерам совместно использовать связанные с ними ресурсы.
Pod, как правило, представляет собой один или несколько контейнеров, которые должны контролироваться как одно приложение. Pod’ы состоят из контейнеров, которые работают в тесном взаимодействии, имеют общий жизненный цикл и должны всегда планироваться на одном узле. Они управляются полностью как единое целое и совместно используют свою среду, тома и пространство IP-адресов. Несмотря на их контейнерную реализацию, Вы, как правило, должны думать о модулях как о едином монолитном приложении, чтобы лучше понять, как кластер будет управлять ресурсами и планированием модуля.
Обычно pod’ы состоят из основного контейнера, который удовлетворяет общему назначению рабочей нагрузки, и, необязательно, некоторых вспомогательных контейнеров, которые облегчают тесно связанные задачи. Это программы, которые получают выгоду от запуска и управления в своих собственных контейнерах, но тесно связаны с основным приложением. Например, в модуле может быть один контейнер, на котором выполняется основной сервер приложений, и вспомогательный контейнер, передающий файлы в общую файловую систему при обнаружении изменений во внешнем репозитории. Горизонтальное масштабирование, как правило, не рекомендуется на уровне модуля, поскольку существуют другие объекты более высокого уровня, более подходящие для данной задачи.
Как правило, пользователи не должны сами управлять модулями, поскольку они не предоставляют некоторые функции, которые обычно требуются в приложениях (например, сложное управление жизненным циклом и масштабирование). Вместо этого пользователям рекомендуется работать с объектами более высокого уровня, которые используют модули или шаблоны модулей в качестве базовых компонентов, но реализуют дополнительные функции.
Контроллеры репликации и наборы репликации (Replication Controllers и Replication Sets)
Часто, работая с Kubernetes, вместо того, чтобы работать с отдельными модулями, вместо этого Вы будете управлять группами идентичных реплицированных модулей. Они создаются из шаблонов pod и могут масштабироваться по горизонтали с помощью контроллеров, известных как контроллеры репликации и наборы репликации.
Контроллер репликации (Replication Controller) представляет собой объект, который определяет шаблон и контроль параметров pod в масштабе идентичных реплик pod’a по горизонтали путем увеличения или уменьшения количества работающих копий. Это простой способ распределить нагрузку и увеличить доступность непосредственно в Kubernetes. Контроллер репликации знает, как создавать новые модули по мере необходимости, поскольку шаблон, очень похожий на определение модуля, встроен в конфигурацию контроллера репликации.
Контроллер репликации отвечает за то, чтобы количество модулей, развернутых в кластере, соответствовало количеству модулей в его конфигурации. В случае сбоя модуля или базового хоста контроллер запустит новые модули для компенсации. Если количество реплик в конфигурации контроллера изменяется, контроллер либо запускается, либо уничтожает контейнеры, чтобы соответствовать желаемому числу. Контроллеры репликации также могут выполнять непрерывные обновления, чтобы переходить от набора модулей к новой версии по одному, сводя к минимуму влияние на доступность приложений.
Наборы репликации (Replication Sets) — это итерация конструкции контроллера репликации с большей гибкостью в том, как контроллер идентифицирует модули, которыми он должен управлять. Наборы репликации начинают заменять контроллеры репликации из-за их более широких возможностей выбора реплик, но они не могут выполнять непрерывные обновления для циклического бэкэнда до новой версии, как это делают контроллеры репликации. Вместо этого наборы репликации предназначены для использования внутри дополнительных модулей более высокого уровня, которые предоставляют эту функциональность.
Как и модули, контроллеры репликации и наборы репликации редко являются единицами, с которыми вы будете работать напрямую. Несмотря на то, что они основаны на конструкции модуля для добавления горизонтального масштабирования и гарантий надежности, им не хватает некоторых тонкодисперсных возможностей управления жизненным циклом, имеющихся в более сложных объектах.
Развертывания (Deployments)
Развертывания являются одной из наиболее распространенных рабочих процедур для непосредственного создания и управления. Развертывания используют наборы репликации в качестве строительного блока, добавляя гибкую функциональность управления жизненным циклом.
Хотя развертывания, построенные с использованием наборов репликаций, могут, по-видимому, дублировать функциональность, предлагаемую контроллерами репликации, развертывания решают многие болевые точки, которые существовали при реализации скользящих обновлений. При обновлении приложений с помощью контроллеров репликации пользователи должны представить план для нового контроллера репликации, который заменит текущий контроллер. При использовании контроллеров репликации такие задачи, как отслеживание истории, восстановление после сбоев сети во время обновления и откат неудачных изменений, либо являются сложными, либо остаются за ответственностью пользователя.
Развертывания — это объект высокого уровня, предназначенный для упрощения управления реплицированными модулями в течение жизненного цикла. Развертывания могут быть легко изменены путем изменения конфигурации, и Kubernetes будет настраивать наборы реплик, управлять переходами между различными версиями приложений и, при необходимости, автоматически поддерживать историю событий и отменять возможности. Поэтому, развертывания будут типом объекта Kubernetes, с которым Вы будете работать чаще всего.
StatefulSet и DaemonSet
Контроллер развертывания использует планировщик Kubernetes для выполнения указанного количества реплик в любом доступном узле с достаточными ресурсами. Такой подход к использованию развертываний часто обоснован для приложений без отслеживания состояния, но непригоден для приложений, которым нужно поддержание постоянных имен или хранилищ. Для приложений, реплика которых должна существовать в каждом узле или в определенном наборе узлов в кластере, контроллер развертывания не отслеживает распределение реплик между узлами.
В работе с такими приложениями вам помогут два ресурса Kubernetes:
- наборы StatefulSet, которые поддерживают состояние приложений за пределами жизненного цикла отдельных модулей pod, например для хранилища;
- наборы Daemonset, которые обеспечивают запуск экземпляров на каждом узле с самых ранних этапов начальной загрузки Kubernetes.
Наборы состояний (StatefulSets)
Это специализированные контроллеры pod, которые предлагают порядок и уникальность. Прежде всего, они используются для более детального управления, когда у Вас есть особые требования, связанные с порядком развертывания, постоянными данными или стабильной сетью. Например, наборы с состоянием часто связаны с ориентированными на данные приложениями, такими как базы данных, которым требуется доступ к тем же томам, даже если они перенесены на новый узел.
Наборы с сохранением состояния обеспечивают стабильный сетевой идентификатор, создавая уникальное (основанное на номере) имя для каждого модуля, которое будет сохраняться, даже если модуль необходимо переместить на другой узел. Кроме того, постоянные тома хранения могут быть перенесены с модулем, когда необходимо перепланирование. Тома сохраняются даже после удаления модуля, чтобы предотвратить случайную потерю данных.
При развертывании или настройке масштаба наборы с сохранением состояния выполняют операции в соответствии с пронумерованным идентификатором в их имени. Это обеспечивает большую предсказуемость и контроль над порядком выполнения, что может быть полезно в некоторых случаях.
Наборы служб (StatefulDeamos)
Это еще одна специализированная форма контроллера pod, который запускает копию pod на каждом узле кластера (или подмножестве, если указано). Это чаще всего полезно при развертывании модулей, которые помогают выполнять обслуживание и предоставлять услуги для самих узлов.
Например, сбор и пересылка журналов, агрегирование метрик и запуск служб, которые расширяют возможности самого узла, являются популярными кандидатами на наборы демонов. Поскольку наборы демонов часто предоставляют базовые сервисы и необходимы по всему кластеру, они могут обойти ограничения планирования модулей, которые не позволяют другим контроллерам назначать модули определенным хостам. Например, из-за своих уникальных обязанностей главный сервер часто конфигурируется как недоступный для обычного планирования модуля, но StatefulDeamons имеют возможность отменять ограничение для каждого модуля, чтобы убедиться, что основные службы запущены.
Задания и cron задания (jobs и cron jobs)
Все рабочие процессы (workloads), которые мы описали, имеют длительный жизненный цикл, подобный сервису. Kubernetes использует рабочий процесс, называемый jobs (задания), чтобы обеспечить процесс, основанный на задачах, при котором работающие контейнеры должны успешно завершиться через некоторое время после завершения своей работы. Задания полезны, если Вам необходимо выполнить одноразовую или пакетную обработку вместо выполнения непрерывного обслуживания.
Cron jobs созданы на основе jobs. Как и обычный cron-демон в Linux и Unix-подобных системах, который выполняет сценарии по расписанию, задания cron jobs в Kubernetes предоставляют интерфейс для запуска заданий с элементом планирования. Задания cron jobs можно использовать для планирования задания на выполнение в будущем или на регулярной основе. Cron jobs в Kubernetes — это, в основном, переопределение классического поведения cron с использованием кластера в качестве платформы вместо единой операционной системы.
Другие компоненты Kubernetes
Помимо рабочих процессов, которые Вы можете использовать в кластере, Kubernetes предоставляет ряд других абстракций, которые помогут Вам управлять Вашими приложениями, управлять сетью и обеспечивать постоянство. Мы обсудим несколько наиболее распространенных примеров далее.
Службы (Services)
До сих пор мы использовали термин «служба» в обычном Unix-подобном смысле: для обозначения долго выполняющихся процессов, часто подключенных к сети, способных отвечать на запросы. Однако в Kubernetes служба — это компонент, который действует как основной внутренний балансировщик процессов и посредник для модулей. Служба группирует логические коллекции модулей, которые выполняют одну и ту же функцию, чтобы представить их как единый объект.
Это позволяет Вам развернуть сервис, который можно отслеживать и направлять во все внутренние контейнеры определенного типа. Внутренние потребители должны знать только о стабильной конечной точке, предоставляемой сервисом. Между тем, service-абстракция позволяет Вам при необходимости масштабировать или заменять бэкэнд-рабочие блоки. IP-адрес службы остается стабильным независимо от изменений в модулях, к которым он направляет. Развертывая services, Вы легко получаете возможность обнаружения и можете упростить конструкцию своего контейнера.
Каждый раз, когда Вам необходимо предоставить доступ к одному или нескольким модулям для другого приложения или внешним потребителям, Вы должны настроить службу. Например, если у Вас есть набор модулей, работающих на веб-серверах, которые должны быть доступны из Интернета, служба предоставит необходимую абстракцию. Аналогичным образом, если Вашим веб-серверам необходимо хранить и извлекать данные, Вам необходимо настроить внутреннюю службу, чтобы предоставить им доступ к модулям базы данных.
Хотя службы по умолчанию доступны только с внутренним маршрутизируемым IP-адресом, их можно сделать доступными за пределами кластера, выбрав одну из нескольких стратегий. NodePort конфигурация работает, открыв статический порт на внешнем сетевом интерфейсе каждого узла. Трафик на внешний порт будет автоматически направляться на соответствующие модули с использованием внутренней IP-службы кластера.
В качестве альтернативы тип службы LoadBalancer создает внешний балансировщик нагрузки для маршрутизации к службе с помощью интеграции балансировщика нагрузки Kubernetes. Менеджер облачного контроллера (cloud controller manager) создаст соответствующий ресурс и настроит его, используя адреса внутренних служб.
Объемы и постоянные объемы (Volumes и Persistent Volumes)
Надежный обмен данными и обеспечение их доступности между перезапусками контейнеров является проблемой во многих контейнерных окружениях. Среды выполнения контейнера часто предоставляют некоторый механизм для прикрепления хранилища к контейнеру, который сохраняется в течение срока службы контейнера, но реализациям обычно не хватает гибкости.
Для решения этой проблемы Kubernetes использует собственную абстракцию томов (volumes), которая позволяет совместно использовать данные всем контейнерам в модуле и оставаться доступными до тех пор, пока модуль не будет завершен. Это означает, что тесно связанные модули могут легко обмениваться файлами без сложных внешних механизмов. Ошибки контейнера в модуле не влияют на доступ к общим файлам. Как только модуль завершается, общий том уничтожается, поэтому он не является хорошим решением для действительно постоянных данных.
Persistent volumes (Постоянные тома) — это механизм выделения более надежного хранилища, не привязанного к жизненному циклу модуля. Вместо этого они позволяют администраторам настраивать ресурсы хранения для кластера, которые пользователи могут запрашивать и запрашивать для модулей, которые они используют. Как только модуль сделан с постоянным томом, политика восстановления тома определяет, будет ли том храниться до тех пор, пока он не будет удален или удален вручную вместе с данными. Постоянные тома можно использовать для защиты от сбоев на основе узлов и для выделения большего объема памяти, чем доступно локально.
Метки и аннотации (Labels и Annotations)
Метка в Kubernetes является семантическим признаком, который может быть присоединен к объекту Kubernetes, чтобы отметить их как часть группы. Затем их можно все выбрать для управления. Например, каждый из объектов на основе контроллера использует метки для идентификации модулей, с которыми они должны работать. Сервисы используют метки для понимания бэкэндов, к которым они должны направлять запросы.
Labels даются в виде простых пар ключ-значение. Каждая единица может иметь более одной метки, но каждая единица может иметь только одну запись для каждого ключа. Обычно в качестве идентификатора общего назначения используется «имя» ключа, но Вы можете дополнительно классифицировать объекты по другим критериям, таким как этап разработки, общедоступность, версия приложения и т.д.
Аннотации — это похожий механизм, который позволяет Вам прикрепить произвольную информацию о значении ключа к объекту. В то время как метки должны использоваться для семантической информации, полезной для сопоставления модуля с критериями выбора, аннотации имеют более свободную форму и могут содержать менее структурированные данные. В общем, аннотации — это способ добавления расширенных метаданных к объекту, который не помогает в целях выбора.
Заключение
Kubernetes — это увлекательный проект, который позволяет пользователям запускать масштабируемые высокодоступные контейнерные рабочие процессы на высокоабстрагированной платформе. Хотя архитектура и набор внутренних компонентов Kubernetes могут поначалу казаться пугающими, их мощь, гибкость и надежный набор функций не имеют аналогов в мире открытого исходного кода. Поняв, как основные строительные блоки сочетаются друг с другом, Вы можете приступить к проектированию систем, которые в полной мере используют возможности платформы для запуска и управления Вашими рабочими процессами в разных масштабах.
Docker: основные команды
Docker Container – технология, которая позволяет автоматизировать процесс развертывания и управления приложениями в среде виртуализации на уровне операционной системы. В основном Docker-контейнеры используются для СI/CD cистем.
В статье рассмотрим 13 самых часто используемых Docker команд на примере Linux-систем. Читать далее «Docker: основные команды»