
Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
tr [options] "SET1" "SET2"
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
echo "something to translate" | tr "SET1" "SET2"
tr "SET1" "SET2" < file-to-translate
tr "SET1" "SET2" < file-to-translate > file-output
Вот некоторые опции:
-c, -C, --complement -> удалить все символы, кроме тех, что в первом наборе
-d, --delete -> удалить символы из первого набора
-s, --squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или "a-z" "A-Z" для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
$ echo "hello linux world" | tr [:lower:] [:upper:] HELLO LINUX WORLD
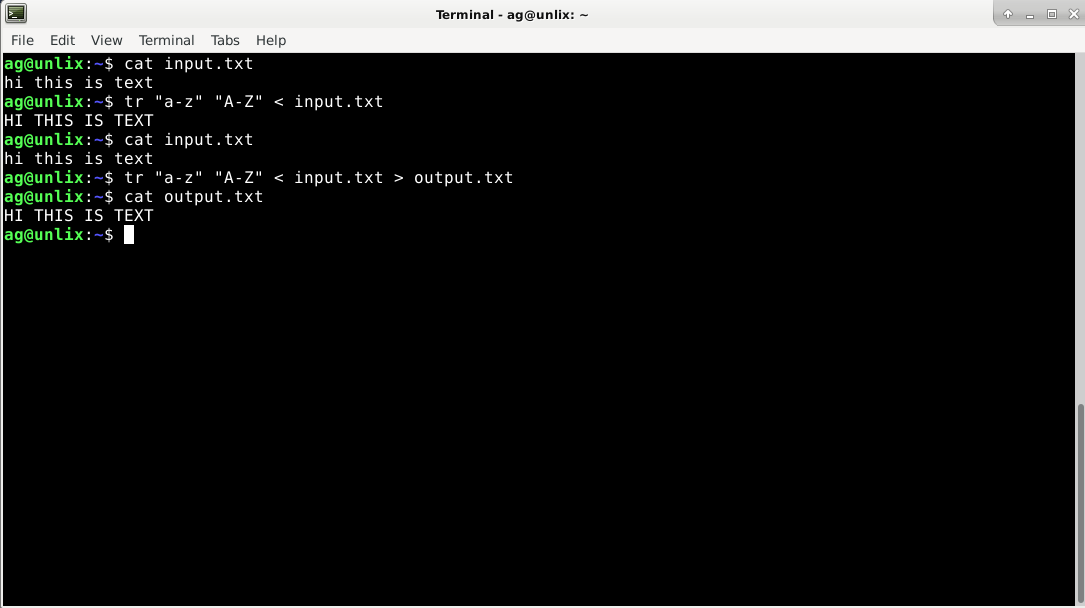
А сейчас сделаем замену из файла input.txt
$ cat input.txt hi this is text $ tr "a-z" "A-Z" < input.txt HI THIS IS TEXT $ cat input.txt hi this is text
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
$ tr "a-z" "A-Z" < input.txt > output.txt $ cat output.txt HI THIS IS TEXT
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
$ echo "hi this is example text" | tr -d "aei" h ths s xmpl txt
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
$ echo "1 please 2 remove 3 all 4 digits" | tr -d [:digit:] please remove all digits
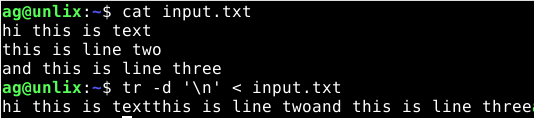
А вот пример команд, которыми можно удалить переносы на новые строки
$ tr -d '\n' < file.txt or $ tr -d '2' < file.txt
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
$ echo "a1b2c3d4" | tr -c 'abcd' '0' a0b0c0d0
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)
$ echo "12345 abcd 67890 efgh" | tr -cd [:digit:] 1234567890

4) Замена пробелов на табуляцию
Для указания пробелов используем – [:space:] , а для табуляции – \t.
$ echo "1 2 3 4" | tr [:space:] '\t' 1 2 3 4
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
$ echo "many spaces here" | tr -s " " many spaces here
Или заменим повторения на символ решетки
$ echo "many spaces here" | tr -s '[:space:]' '#' many#spaces#here
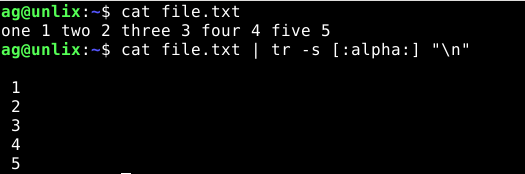
6) Заменить символы из набора на перенос строки
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
$ cat file.txt one 1 two 2 three 3 four 4 five 5 $ cat file.txt | tr -s "[:alpha:]" "\n" 1 2 3 4 5
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
$ cat file.txt
word1 word1 word2 word3 word4 word4
$ cat file.txt | tr -cs "[:alnum:]" "\n" | sort | uniq -c | sort -rn
2 word4
2 word1
1 word3
1 word2
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) – это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
tr 'a-z' 'p-za-n'
Простая команда для демонстрации вышеуказанной теории:
$ echo 'abg' | tr 'ab' 'ef' efg
Полезно при шифровании электронных адресов:
$ echo 'cryptography@example.com' | tr 'A-Za-z' 'N-ZA-Mn-za-m pelcgbtencul@rknzcyr.pbz
Вывод
tr – это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)
$ echo “12345 abcd 67890 efgh” | tr -cd [:digit:]
abcd efgh
Исправьте, пожалуйста. Вывод команды будет 1234567890
Спасибо, исправлено